cpp学习上遇到的问题
1. 2023/08/29
析构函数和复制构造函数不能是模板。若声明了可用复制构造函数的类型签名实例化的模板构造函数,则替而使用隐式声明的复制构造函数。
成员函数模板不能为虚,且派生类中的成员函数模板不能覆盖来自基类的虚成员函数。
重载规则规定当模板实例化函数和非模板函数(或者称为“正常”函数)匹配优先级相当时,优先使用“正常”函数。
- 函数模板重载
- 重载运算符为成员函数和友元函数时关键的区别在于成员函数具有this指针,而友元函数没有this指针。
2. 2023/08/29
2.1. unicode
字符集定义了字符和数字(一般用16进制表示,又名码点)的对应关系,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和数字的对应关系,
计算机显示文字或者存储文字,就是一个查表的过程。而字符编码规定了如何将字符的编号存储到计算机中。如果使用了类似 GB2312 和 GBK 的变长存储方案(不同的字符占用的字节数不一样),那么为了区分一个字符,到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码
- 字面常量(literal constant)即无需定义可以直接写出来的量。字面常量的值一望便知,但是他的数据类型往往不能被准确分辨(尤其是使用auto时)。
- 编译期可知的值“享有特权”,它们可能被存放到只读存储空间中。
这里的编码指的是字符对应的数如何映射为二进制数,utf-8中一个数字可能映射为1-4字节的二进制编码,utf-32是所有的数都映射为4字节,utf-16则是用2或4字节来实现映射,宽字符wchar_t则是根据实现定义,它是32位,在Linux和许多其他非Windows系统上保存 UTF-32,但在 Windows上是16位,保存 UTF-16代码单元。
代码单元是字符编码系统(例如 UTF-8 或 UTF-16)使用的基本组件。字符编码系统使用一个或多个代码单元对 Unicode代码点进行编码。
2.2. 非类型形参的局限:
- 浮点数不可以作为非类型形参,包括float,double。具体原因可能是历史因素,也许未来C++会支持浮点数;
- 类不可以作为非类型形参;
- 字符串不可以作为非类型形参;
- 整形,可转化为整形的类型都可以作为形参,比如int,char,long,unsigned,bool,short(enum声明的内部数据可以作为实参传递给int,但是一般不能当形参);
- 指向对象或函数的指针与引用(左值引用)可以作为形参。
- this is an example
2.3. 非类型实参的局限:
- 实参必须是编译时常量表达式,不能使用非const的局部变量,局部对象地址及动态对象;
- 非const的全局指针,全局对象/全局变量(下面可能有个特例)都不是常量表达式;
- 由于形参的已经做了限定,字符串,浮点型即使是常量表达式也不可以作为非类型实参 ;
- 当模板非类型形参为对象指针或引用时,则对于实参而言他们指向的对象不能是字符串字面值、临时量或者数据成员或者其他子对象。
- 这些限制在每个的C++版本中有所放送,额外的限制:
- C++11前,该对象必须有外部链接(external linkage)
- C++14前,该对象必须有外部链接或者内部链接
备注:常量表达式基本上是字面值以及const修饰的变量
- 这些限制在每个的C++版本中有所放送,额外的限制:
- 紧接上条,如果非类型形参类型为对象指针,则实参必须传入完整对象的地址,直接用取地址符取对象地址,不能是指向该对象的指针
2.3.1. 函数模板中模板实参的推导
- 如果模板函数中数组类型形参(不是模板列表中的模板形参)不是引用传递而是值传递,数组会自动降一维,成为一个指向一维数组的指针
1
2
3
4
5template<class T>
void f(T);
int a[3];
f(a); // P = T, A = int[3], adjusted to int*: deduced T = int* - 数组在做模板函数的实参时,若模板函数形参不是引用或指向数组的指针(列如二维数组退化为指向一维数组的指针),则不会进行模板实参推导
1
2template<size_t w, size_t h>
void f(double (&s)[w][h]){cout<<s[0]<<endl;} //若去掉引用,则w不会被正确推导,但h可以,因为此时退化为一维数组指针
2.4. 编译时常量表达式
- 整形常量为如果被常量表达式初始化则为常量表达式 ,也可以用于初始化其他常量表达式,其他类型目前未知
- constexpr 所表示的对象为const,被放置在只读内存中,是在编译期就可以被处理识别的值, 并且对象一定要被正确初始化
- constexpr 所表示的函数的参数和返回值都应为字面值或编译期常量(该常量也应被加上constexpr说明符),当多个不可知量调用constexpr函数时,该函数所表现出的形式为普通函数,所以constexpr的返回值不一定是const
- 在C++11中,除了void外的所有内置类型,以及一些用户定义类型都可以是字面值类型,因为构造函数和其他成员函数可能是constexpr(c++14constexpr函数可以返回void)
- Point的构造函数可被声明为constexpr,因为如果传入的参数在编译期可知,Point的数据成员也能在编译器可知。因此这样初始化的Point就能为constexpr
- 声明为constexpr的静态成员对象是内联的,在odr-use时可以不用在类外定义,lambda表达式中被odr-use的变量一定要被捕获,被捕获的变量不论是不是constexpr都不能用于常量表达式
1 | |
- 在函数体内定义的constexpr变量不能用于初始化constexpr引用,constexpr引用必须被静态存储或线程局部常量表达式初始化(也称左值核心常量表达式)
- constexpr的变量也是在运行期给予地址的,所以取地址不是常量表达式
- constexpr变量模板,之前我们需要用类静态数据成员来表达的东西,使用变量模板可以更简洁地表达。constexpr 很合适用在变量模板里,表达一个和某个类型相关的编译期常量。
1
2
3
4
5
6
7
template <class T>
inline constexpr bool
is_trivially_destructible_v =
is_trivially_destructible<
T>::value; //判断类是否能平凡析构,指是否不调用析构函数也能正确回收资源
个人对于常量表达式的理解目前仍旧比较浅显,cppreference关于constexpr的叙述看的好像明白又好像完全不懂…
2.5. 隐式转换
- 常见的隐式转换有
- 整形之间以及整形浮点数(算术类型)
- nullptr和其他类型之间的转换
- 函数到函数指针的转换
- up-casting
- 一个隐式类型转换序列包括一个初始标准转换序列、一个用户定义转换序列、一个第二标准转换序列,也就是说不存在什么两步转换问题,本身转换序列最少可以转换1次,最多可以三次。两次转换当然没问题了。唯一会触发问题的是出现了两次用户定义转换,因为隐式转换序列里只允许一次用户定义转换,语言标准也规定了不允许出现多余一次的用户定义转换:
2.6. 设计模式
观察者模式是一种行为设计模式, 允许你定义一种订阅机制, 可在对象事件发生时通知多个 “观察” 该对象的其他对象。
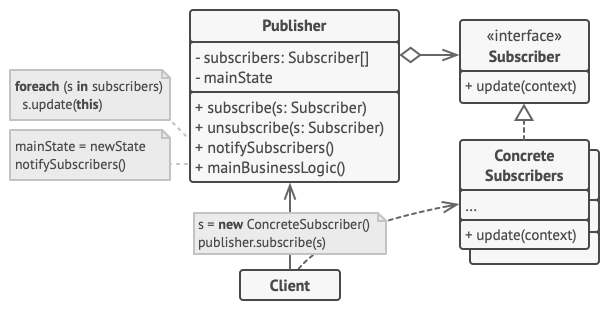
奇怪的重复模板模式 (CRTP )
2.7. 智能指针
- shared_ptr的析构会将引用计数减一,但lambda闭包中的ptr还持有一个引用,引用计数不会变为0
2.8. const成员函数
const成员函数即表示不会修改类的非mutable数据成员,const修饰成员函数的意义就在于c++规定const类对象在调用非const成员函数时会报错,当成员函数的const和非const版本同时存在时,非const对象只会调用非const成员函数,const对象只会调用const成员函数
2.9. 右值
- std::move除了转换它的实参到右值以外什么也不做,有一些提议说它的名字叫rvalue_cast之类可能会更好。虽然可能确实是这样,但是它的名字已经是std::move,所以记住std::move做什么和不做什么很重要。它只进行转换,不移动任何东西。
- 右值可以用来初始化右值引用,这种情况下该右值所标识的对象的生存期被延长到该引用的作用域结尾。
- static_cast
(v) - 如果T的类型为左值引用或者对函数指针的右值引用,结果为左值,同时T若为右值引用,返回结果为相应类型的亡值,其生命周期等于引用的生命周期
- 同时,static_cast 不太适用于向下转型,基类的左值(引用)转型为派生类左值引用时必须保证基类为派生类中的基类子对象(顾名思义为子类中is_a基类的部分),结果可转为类型为D的封闭对象(enclosing object),否则UB
- 所以,static_cast在运行时不进行任何检查来确保被转换的对象实际上是目标类型的完整对象。因此,程序员需要确保转换是安全的。另一方面,它不会产生dynamic_cast的类型安全检查的开销。
2.10. 模板杂类
c++模板是图灵完全的,可以在编译期对模板类进行求值,要进行编译期编程,最主要的一点,是需要把计算转变成类型推导。
现代c++编程实战中关于模板编译期计算的讲解T&& 当T作为成员函数模板形参时,表现出通用引用,或转发引用,根据传递的左值或者右值来决定是左值还是右值引用,而如同complex&&此类直接指定类名或者在模板类中指定T,亦或者将T&&前加上cv限定,一般都属于右值引用
1
2template <typename T>
complex(T&&){} // forward reference- 一般来说都用std::forward
(param)来转发通用引用(有条件的转为右值引用),用std::move将右值引用转为右值,且不会影响cv限定
- 一般来说都用std::forward
如果你在按值返回的函数中,返回值绑定到右值引用或者通用引用上,需要对返回的引用使用std::move或者std::forward。要了解原因,考虑两个矩阵相加的operator+函数,左侧的矩阵为右值(可以被用来保存求值之后的和):
1
2
3
4
5
6Matrix //按值返回
operator+(Matrix&& lhs, const Matrix& rhs)
{
lhs += rhs;
return std::move(lhs); //移动lhs到返回值中
}通过在return语句中将lhs转换为右值(通过std::move),lhs可以移动到返回值的内存位置。如果省略了std::move调用,
1
2
3
4
5
6Matrix //同之前一样
operator+(Matrix&& lhs, const Matrix& rhs)
{
lhs += rhs;
return lhs; //拷贝lhs到返回值中
}lhs是个左值的事实,会强制编译器拷贝它到返回值的内存空间。假定Matrix支持移动操作,并且比拷贝操作效率更高,在return语句中使用std::move的代码效率更高。
模板在使用之前必须先声明。模板的使用由友元声明构成,不是由模板的声明构成。实际的模板声明必须在友元声明之前。例如,编译系统尝试链接以下示例中生成的目标文件时,对未实例化的 operator<< 函数,会生成未定义错误。
- 友元类,友元函数的相关知识
- 在 C++11 中,一个类有两种形式的友元声明:如果最内层的命名空间中找不到任何具有该名称的现有类,则第一种形式引入新的类 F。 C++11:第二种形式不引入新的类;当类已声明时,可以使用该形式,而当将模板类型参数或 typedef 声明为 friend 时,必须使用该形式。
1
2friend class F;
friend F; - 如果声明以前未声明的 friend 函数,则该函数将被导出到封闭非类范围。friend 声明中声明的函数被视为已使用 extern 关键字声明。若使用
- 在 C++11 中,一个类有两种形式的友元声明:
- 友元类,友元函数的相关知识
类模板的静态成员变量是所有同类型的类模板实例共享的一块数据。当多个目标文件中声明了同一类模板的同类型实例后,必然会产生跨目标文件链接。
在函数模板中的所有if语句的分支都会被实例化(instantiated)。实例化后的代码是否有用是在run-time决定,而函数调用的实例化是在complie-time。
缺省情况下,实例会进入特殊地址区域,链接程序会识别并丢弃重复项。
注意,在本地mingw gcc环境下对多个源文件都引入头文件中关于模板特定实参的实例化并统一编译,结果成功,表明链接器会丢弃重复的实例化
2.11. lambda
- lambda主体不能捕捉静态存储期限变量
- lambda主体在读取被常量表达式初始化并被const修饰的整形或枚举常量或者constexpr修饰的常量的值时,可以不进行捕获
- 如果存在捕获默认项,则当前对象(*this)可以被隐式捕获。如果隐式捕获,则始终通过引用进行捕获,即使捕获默认项是=。
- const lambda
- 语法类似于:
const auto a = [&i]()constexpr{ return i; }; - 创建const闭包类型对象,只能调用const成员函数,也就是重载的operator()函数必须为const成员函数,这样在说明符序列中也不能加入mutable关键字
1
2
3
4
5
6
7
8
9
10
11
12
13#include <iostream>
int foo(int i)
{
int b = 50;
const auto a = [&i](int b)constexpr{ i = b;return i; };
a(b);
return i;
}
int main()
{
std::cout << foo(42) << std::endl;
return 0;
} - 这里i可以被改变的原因是i并不是一个常量引用(const int&),在const成员函数中引用不可以被更改指的是在这里i的类型为是引用常量,众所周知c++中并不存在引用常量,因为引用被初始化后就是一个常量,不可以再次被绑定到其他左值或右值上,若想要达到i引用的数据值不被改变,可以在foo传参时将i的类型改为const int
- 语法类似于:
- odr-use
- lambda函数主体在ODR-use自动存储期变量或者this指针所指代的实体(entity)时,必须要隐式或显式的捕获它
- 如果lambda函数的主体odr-use被复制捕获的实体,则访问闭包类型的成员。如果它没有odr-use该实体,则访问原始对象(不发生捕获)。
- 在默认捕获为复制捕获的lambda主体中,任何可捕获实体的类型都像被捕获了一样(因此如果lambda不可变,则通常会添加const限定符),即使该实体在未求值的操作数中且未被捕获(例如在decltype中)。
- 任何被lambda函数隐式或显式捕获的变量都是ODR-use的
2.12. 成员函数指针
- 指向作为类 C 的成员的非静态成员函数 f 的指针,能准确地以表达式 &C::f 初始化。在 C 的成员函数内,如 &(C::f) 或 &f,这样的表达式不构成成员函数指针。
1 | |
2.13. 数据成员指针
指向作为类 C 的成员的非静态数据成员 m 的指针,能准确地以表达式 &C::m 初始化。在 C 的成员函数中,如 &(C::m) 或 &m 这样的表达式不构成指向成员指针
类定义是一种类型声明,存在于代码块中,并没有分配内存空间;对类的数据成员取地址,得到的是类的数据成员在类内的相对偏移量;
1 | |
2.14. 虚函数
2.14.1. 从汇编层面理解虚函数的实现
1 | |
经x86-64_gcc7.5编译器编译后, 汇编代码如下:
1 | |
以下是对主函数汇编段代码的解释:
push rbp:将 rbp 寄存器的值压入栈中,保存当前的基址指针。
mov rbp, rsp:将 rsp 寄存器的值赋给 rbp 寄存器,设置新的基址指针
push rbx:将 rbx 寄存器的值压入栈中,保存当前的基址寄存器
sub rsp, 24:将 rsp 寄存器的值减去 24,为局部变量分配空间
mov edi, 8:将 8 赋给 edi 寄存器,作为 operator new 的参数,表示要分配 8 个字节的内存
call operator new(unsigned long):调用 operator new 函数,为 Child 对象分配内存空间,并将返回的地址放在 rax 寄存器中
mov rbx, rax:将 rax 寄存器的值赋给 rbx 寄存器,保存 Child 对象的地址
mov rdi, rbx:将 rbx 寄存器的值赋给 rdi 寄存器,作为 Child::Child() 的参数,表示要构造 Child 对象
call Child::Child() [complete object constructor]:调用 Child::Child() 函数,完成 Child 对象的构造过程
mov QWORD PTR [rbp-24], rbx:将 rbx 寄存器的值(Child 对象的地址)赋给 [rbp-24] 指向的内存单元(局部变量)
mov rax, QWORD PTR [rbp-24]:将 [rbp-24] 指向的内存单元(局部变量)的值(Child 对象的地址)赋给 rax 寄存器
mov rax, QWORD PTR [rax]:将 [rax] 指向的内存单元(Child 对象中第一个成员变量)的值(虚函数表指针)赋给 rax 寄存器
mov rax, QWORD PTR [rax]:将 [rax] 指向的内存单元(虚函数表中第一个函数指针)的值(虚函数地址)赋给 rax 寄存器
mov rdx, QWORD PTR [rbp-24]:将 [rbp-24] 指向的内存单元(局部变量)的值(Child 对象的地址)赋给 rdx 寄存器
mov rdi, rdx:将 rdx 寄存器的值(Child 对象的地址)赋给 rdi 寄存器,作为虚函数的参数,表示要调用 Child 对象的虚函数
call rax:调用 rax 寄存器中保存的函数地址(虚函数地址),执行 Child 对象的虚函数,并将返回值放在 rax 寄存器中
mov eax, 0:将 0 赋给 eax 寄存器,作为 main 函数的返回值
add rsp, 24:将 rsp 寄存器的值加上 24,释放局部变量占用的空间
pop rbx:从栈中弹出一个值,赋给 rbx 寄存器,恢复之前保存的基址寄存器
pop rbp:从栈中弹出一个值,赋给 rbp 寄存器,恢复之前保存的基址指针
ret:从栈中弹出一个值,作为返回地址,并跳转到该地址继续执行。
总结来说,比较老旧的编译器无法直接对指针或者引用下虚函数的调用进行静态绑定(值语义下可以,值语义指的是直接使用对象的.方法调用虚函数),即直接使用call functionname的做法,必须通过当前指针所指向的对象,查找其内存模型的第一个成员地址,也就是vptr的位置,之后通过vptr找到其指向的vtbl(虚表), vtbl是可以看作一个存放虚函数地址的数组,单个继承下无论是父类还是子类其每个虚函数的的偏移量在虚表中是相同的(索引是相同的),运行期可以直接通过该虚函数的地址来调用虚函数。所以编译器在编译期就已经构建并维护了虚指针和虚表,具体创建时间是在该类的对象的构造函数被调用之后,在较新的编译器中编译相同代码,编译器可能直接对虚函数进行静态绑定, 在c++11之后,子类使用final来覆写虚函数后,用子类指针或引用来调用虚函数,也可以做到静态绑定
2.14.2. 虚析构函数
通过指向基类的指针删除对象会引发未定义行为,除非基类的析构函数是虚函数:
1
2
3
4
5
6
7
8
9
10
11class Base
{
public:
virtual ~Base() {}
};
class Derived : public Base {};
Base* b = new Derived;
delete b; // 安全析构函数可以声明为纯虚的,例如对于需要声明为抽象类,但没有其他可声明为纯虚的适合函数的基类。纯虚析构函数必须有定义,因为在销毁派生类时,所有基类析构函数都会被调用:
1 | |
几个讲解虚函数讲的不错的博客:
虚函数的内存分布
C++基本概念在编译器中的实现
多态实现-虚函数、函数指针以及变体
2.15. 虚基类
这里贴出一篇博客,讲解了虚基类在内存中的分布
3. 2023/9/1
3.1. std::bind
1 | |
- std::bind为每个实参创建了bind对象里的副本,每次调用bind对象时,调用的是传递给lambda表达式的本地副本。在如上的例子中,std::move(data)使用移动构造创建了本地副本(左值),之后每次调用函数副本时,调用的都是该副本
3.2. 关于初始化的一些想法,表述上可能有纰漏,但根据代码执行来看应该是正确的
3.2.1. 值初始化
形式: T() / T{}
若T为类对象且有用户提供(除了在类定义内直接显式指定default的默认构造函数都可以称为用户提供的默认构造函数)的默认构造函数,则对对象进行默认初始化;
若T为类对象且T只有隐式生成的默认构造函数,或者只有在类定义内指定default的默认构造函数,换而言之,如果显式定义/预置/删除了转换构造,拷贝或者移动构造(经过实验发现赋值操作不会影响默认构造函数的隐式生成),那么默认构造函数就不会隐式生成,如果默认构造函数隐式生成或被显式预置(后者前提是没有用户提供或者显示删除的默认构造函数),则会首先对类对象进行零初始化(即所有bit位置零),之后会通过语义限制检查默认构造函数是否为重要(non-trivial)的默认构造函数,来对其中的对象进行默认初始化
trivial default constructor :
- 不是用户提供(即隐式生成或者首次声明时就显式预置)
- 对应的类没有虚函数或者虚基类
- 直接基类拥有trivial default ctor
- 非静态成员同上
所有标准容器(std::vector、std::list 等)在以单个 size_type 实参进行构造或由对 resize() 的调用而增长时值初始化它们的各个元素,除非它们的分配器定制 construct 的行为。
3.2.2. 默认初始化
- 形式: T obj/ new T;
- 调用无参默认构造函数,并对没有在成员初始化列表进行指明或者没有默认成员初始化器的非静态成员和基类成员进行默认初始化
- 注意: 对自动/动态存储期非类类型成员进行默认初始化时会获得不确定的值,这也是我想讨论的重点,比如对int成员变量进行默认初始化之后,使用其赋值会导致UB
- 使用默认初始化初始化const修饰的对象时,若为类对象必须有用户定义或提供的默认构造函数,或者每个非静态成员都有成员默认初始化器。最重要的是对应的基类子对象也必须满足上述条件
- tips: member initializer list 中没有出现但在函数主体中出现的成员变量在进入函数主体前被默认初始化,这要求其必须具备默认构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include <string>
struct T1 { int mem; };
struct T2
{
int mem;
T2() { } // "mem" is not in the initializer list
};
int n; // static non-class, a two-phase initialization is done:
// 1) zero-initialization initializes n to zero
// 2) default-initialization does nothing, leaving n being zero
int main()
{
[[maybe_unused]]
int n; // non-class, the value is indeterminate
std::string s; // class, calls default ctor, the value is "" (empty string)
std::string a[2]; // array, default-initializes the elements, the value is {"", ""}
// int& r; // error: a reference
// const int n; // error: a const non-class
// const T1 t1; // error: const class with implicit default ctor
[[maybe_unused]]
T1 t1; // class, calls implicit default ctor
const T2 t2; // const class, calls the user-provided default ctor
// t2.mem is default-initialized (to indeterminate value)
}若用clang编译器进行编译,输出t1.mem会发现是随机值,用gcc编译器进行编译会发现编译器给出‘uninitiated value’警告但仍然进行了零初始化,若改写为T1 t1{},则都能正常编译并对进行mem零初始化,这就是我认为值初始化和默认初始化的最大区别所在;
3.2.3. 静态成员的初始化
- 具有static(全局变量或static声明)或 thread 存储期限的非局部变量在程序开始前被初始化,存放在全局区,先进行静态初始化,再进行动态初始化, 全局区分为已被初始化的段(.data段),和未被初始化的段(.bss段)
- 静态初始化一般来说就是指零初始化和常量初始化,动态初始化在 cppreference中并没给出明确定义,网络上对于这方面的相关资料也甚少,但值得注意的是,若没有被常量初始化的静态非局部变量在其他初始化进行前都会进行零初始化,之后会根据变量的定义来判断是否改变变量的值,但变量此时必须出现定义,若无定义则会报undefined reference 错误!!
- 动态初始化一般来说(有别的像无序或部分有序,太复杂)是按照静态非局部变量的定义顺序来进行初始化的
- static 局部变量 拥有静态存储期限,但初始化是在第一次进入scope 作用域并执行到变量声明时初始化,除非他是被 零初始化 (加载程序时被设为0,一般存储在BSS段)或者 常量初始化(编译时间),这让他们可以像全局变量一样在程序开始前被初始化
- 具有自动和动态存储期的非类变量的默认初始化,生成具有不确定值的对象(静态和线程局部对象的初始化为零)。
- 引用和常量标量对象不能被默认初始化。
- 标量类型(scalar types)包括integral,reference,floating-point, pointer…………………………..
- 静态数据成员(static data members) 在声明内联或constexpr时指定initialzer , 在类外不需要重定义,甚至在odr-use时也不需要定义,然而对于普通const成员来说,只有int类型的数据才可以拥有initializer,并且在odr-use时也需要在类外重新声明,但这时不能给出初始化器
- 总结就是类静态成员在类中声明时是不会默认初始化的,可以在类外定义进行动态初始化,在类外的静态数据可以直接默认初始化.
3.2.3.1. 2023/11/1 更新动态初始化
在动手查看过各静态变量汇编层面的动态初始化后,对动态初始化有了更多的认识
代码文件及汇编代码在complier explore,编译器为x86-64 clang9.0;
- 对于未初始化的普通数据类型静态或全局变量(即没有初始化器)来说, 其被储存在.bss段中且这些0变量本身并没有保存在可执行文件或者动态链接库文件中,但是其总内存段大小和起止位置在加载件时被统计出来。
- C++ name-mangling机制把这类数据以及局部静态未初始化或者零初始化或者动态初始化变量命名为_ZZ3fooiE开头的变量,用于表示一个静态变量的实际存储位置,根据下面对于动态初始化局部静态变量的汇编代码可以看出,编译器它调用了一些C++运行时库的函数,如__cxa_guard_acquire和__cxa_guard_release,来保证初始化的线程安全和一次性(详情见内存屏障)
1
2
3
4
5
6
7
8
9
10cmp byte ptr [guard variable for foo(int)::staticLocalInitVar], 0
jne .LBB1_3
movabs rdi, offset guard variable for foo(int)::staticLocalInitVar
call __cxa_guard_acquire
cmp eax, 0
je .LBB1_3
call fd()
mov dword ptr [_ZZ3fooiE18staticLocalInitVar], eax
movabs rdi, offset guard variable for foo(int)::staticLocalInitVar
call __cxa_guard_release
- C++ name-mangling机制把这类数据以及局部静态未初始化或者零初始化或者动态初始化变量命名为_ZZ3fooiE开头的变量,用于表示一个静态变量的实际存储位置,根据下面对于动态初始化局部静态变量的汇编代码可以看出,编译器它调用了一些C++运行时库的函数,如__cxa_guard_acquire和__cxa_guard_release,来保证初始化的线程安全和一次性(详情见内存屏障)
- 对于有初始化器但不是常量初始化的普通数据类型静态或全局变量来说,其被存储在.data段中,但编译阶段被初始化为0,其被真正初始化的阶段在运行期,program startup的阶段,在主函数执行之前被无序,偏序,或正序初始化。对于clang为每个静态数据成员在编译阶段分配了其初始化的,名称为__cxx_global_var_init.num的函数代码,到startup时会被__start函数调用
- 无序初始化针对模板类没有被特化的静态数据成员(当然前提是该数据成员不是在类中被赋值的常量整形成员,也不是指定constexpr的内联静态成员),其生成函数的num不一定在它之后声明的变量之前
- 偏序初始化针对内联静态变量
- 其余静态变量或普通类的静态数据成员在同一翻译单元中按照代码顺序动态初始化
- 对于class类型的全局成员来说,.data段将其非静态数据成员全部零初始化,并且构造函数也在startup阶段被调用,析构函数在主函数退出后也被调用
- 还有一种动态初始化可以提早发生在编译阶段,其必须满足以下条件
- 初始化的动态版本不改变命名空间作用域中任何先于其初始化的对象的值
- 初始化的静态版本在被初始化变量中产生的值,与当所有不要求静态初始化的变量都被动态初始化时,由动态初始化所生成的值相同。
但这只是可能提前初始化,并不保证一定会
1 | |
简而言之,d1在程序开始前被赋0,这是静态初始化,之后被赋1,这是动态初始化,但由于某些规则该变量的动态初始化可以被提至编译时间,也就是静态初始化为1,所以d2的值也是不确定的,虽然在本地表现出被动态初始化为1的结果
-[] 依然困惑于动态初始化的局部静态变量,在汇编码中没有找到其在.data段被分配内存,莫非仍然在.bss段被分配内存?
3.3. internal linkage && external linkage
- #pragma once 只能作用于某个具体的文件,而无法向 #ifndef 那样仅作用于指定的一段代码
- 具有内部链接性质的变量可以在头文件中定义,这样会在每个翻译单元内定义不同实体,但由于该变量只在单文件中可见于是不会引发多重定义的问题, 但是会引发代码冗余
- 具有外部链接性质的变量或者函数若声明inline,则会在编译时将变量名替换为变量值 / 函数名替换为函数体, 此时可以在头文件中定义
- 类类型虽然在cppreference中标注类的名称具有外部链接,但在源文件中使用类时(比如构造函数,成员函数等等时),若只在开头标注class complex;是会导致编译错误的,必须要引入class头文件,但是类的静态数据成员和成员函数都具有外部链接,可以在类外定义(另一个源文件,若在头文件定义,需在类外声明inline,若在类内则不需要,因为在类内定义是隐式内联的),根据ODR原则可知ODR允许类类型在多个翻译单元中定义,特别地,对于需要该类类型完整定义的翻译单元中,必须有且仅有该类类型的一个定义,并且在满足特定条件时,如同整个程序中只有一个定义。
- 匿名命名空间也不要在头文件定义,因为每个引入该命名空间的源文件都会为自己创建一份独特命名的命名空间,可能会导致很多意外情况发生
讲述c++编译时会出现多重定义,链接错误等error原因的博客
3.4. C、C99、ANSI C 和 GNU C 之间的区别
标准化之前的一切一般被称为“K&R C”,以著名的书(第一版和第二版)命名,C语言的发明者丹尼斯·里奇(Dennis Ritchie)是作者之一。这就是 1972 年至 1989 年的“C 语言”。
第一个 C 标准于 1989 年由美国国家标准协会 ANSI 在全国发布。此版本称为 C89 或 ANSI-C。从 1989 年到 1990 年,这就是“C 语言”。
次年,美国标准被国际接受并由 ISO 发布(ISO 9899:1990)。此版本称为 C90。从技术上来说,它与C89/ANSI-C是相同的标准。从形式上来说,它取代了 C89/ANSI-C,使它们变得过时。从 1990 年到 1999 年,C90 是“C 语言”。
请注意,自 1989 年以来,ANSI 与 C 语言没有任何关系,只是作为 ISO 标准的众多实例之一。现在在美国通过INCITS完成,C 标准在美国的正式名称为 INCITS/ISO/IEC 9899。就像在欧洲称为 EN/ISO/IEC 一样。
仍在谈论“ANSI C”的程序员通常不知道它的含义。ISO 通过 ISO 9899 标准“拥有”C 语言。
1995 年发布了一个小更新,有时称为“C95”。这不是重大修订,而是正式命名为 ISO/IEC 9899:1990/Amd.1:1995 的技术修订。主要的变化是引入了广泛的字符支持。
1999年,C标准进行了重大修订(ISO 9899:1999)。该版本的标准称为 C99。从 1999 年到 2011 年,这就是“C 语言”。
2011年,C标准再次发生变更(ISO 9899:2011)。这个版本称为C11。该语言中添加了各种新功能,例如_Generic、和线程支持。_Static_assert此次更新重点关注多核、多处理和表达测序。从 2011 年到 2017 年,这就是“C 语言”。
2017年,C11进行了改版,解决了各种缺陷报告。该标准非正式地称为 C17 或 C18。它于 2017 年完成(并使用__STDC_VERSION__= 201710L),但由 ISO 发布为 9899:2018,因此 C17/C18 之间存在歧义。它不包含任何新功能,仅包含更正。它是 C 语言的当前版本。
该委员会正在制定一项名为“C23”/“C2X”的草案,计划于 2023 年发布(但官僚主义的车轮磨得很慢,请检查ISO 的状态)。最后的工作草案 N3096 可在此处找到。
其中包含许多小缺陷报告修复,例如 C17/C18,但也包含许多重大更改和新功能。这是一个主要版本。
“C99 strict”可能是指强制编译器严格遵循标准的编译器设置。C 标准中有一个术语“conformedimplementation” 。本质上它的意思是:“这个编译器实际上正确地实现了C语言”。正确实现 C 语言的程序正式称为严格符合程序。此类程序也可能不包含任何形式的定义不明确的行为。
“GNU C”有两个含义。作为 GNU 编译器集合 (GCC) 一部分的 C 编译器本身。或者它可能意味着 GCC C 编译器使用的非标准默认设置。如果您使用它进行编译,gcc program.c那么您就不会根据 C 标准进行编译,而是根据非标准 GNU 设置进行编译,这可能被称为“GNU C”。例如,整个 Linux 内核是用非标准 GNU C 编写的,而不是用标准 C 编写的。
4. 未完成的学习任务
- c++程序加载时的内存模型(编译期内存的分配以及运行期内存的分配)
栈、栈帧与函数调用
COMPILER, ASSEMBLER, LINKER AND LOADER: A BRIEF STORY